
Introducing Microservices

You might have heard the buzzword Microservices in many engineering talks and conferences. Most of the big companies have started with monolithic architecture and then moved to microservices to host applications at scale. Netflix and Uber started with monolithic and then moved to the microservices pattern.
We have already seen the pain points associated with monolithic applications.
In this chapter, we'll look at the microservices architectural style and see how they solve the problems associated with the monolithic way of building applications.
There is no concrete definition of microservices but here's the most commonly used one:
Microservices is an architectural style that structures an application as a collection of loosely coupled services for handling different business capabilities.
The above definition might be difficult to grasp on the first read! Let's break this down at the fundamental level and understand more:
What are loosely coupled services?
A service is like a mini-application that is self-contained and can handle a particular business requirement independently. It has its own database and no other service can directly modify its database.
However, sometimes two or more services can also share the same database. An application is composed of different services like authorization, inventory management, transactions, payments, etc. Each of these services is implemented as a different module and can be written in different programming languages and can even use a different database to best suit its use case.
For example, the inventory management service can be written in NodeJs and use MongoDB while the payments service can be written in Go and use the MySQL database.
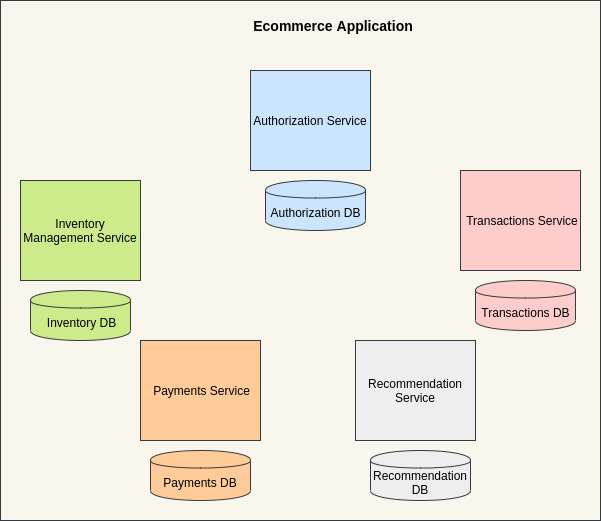
As seen in the above image, an e-commerce application has different services like authorization, inventory management, transactions, payments, and recommendation.
A service exposes some endpoints called application programming interfaces (APIs) that can be used for communication with the other services. The authentication service can talk to the transactions service using the synchronous HTTP/RPC calls or by using the asynchronous events model. We will look at these methods of communication later in the chapter.
Let's consider one example of an e-commerce application:
When a user clicks on the "Place Order" button on the application user interface, the front-end client makes an API request to the back-end server. This request is first routed to the authentication service to check if the user's credentials are valid (required if only signed-in users can place an order). If the user credentials are valid, the authentication service forwards this request to the inventory management service to check if the product is available. The request is then forwarded to the payments service and on successful payment, the user is sent a confirmation email and/or an SMS using the confirmation service.
A lot is going on here! You might have some questions about the above transaction flow. This will make sense once we start learning more about transaction management in microservices.
Recap on services: A service is a self-contained entity used for performing a particular business requirement.
Got it, but what does the term loosely coupled mean?
When you say, an application is built of loosely coupled services, it simply means two services are not dependent on each other. They have their world and an error/fault in one service cannot take down any other service in particular.
Services have their world (read application code and database) and they communicate using synchronous HTTP/RPC calls or asynchronous messaging with the rest of the world.
The Transition from Monolith to the Microservices pattern
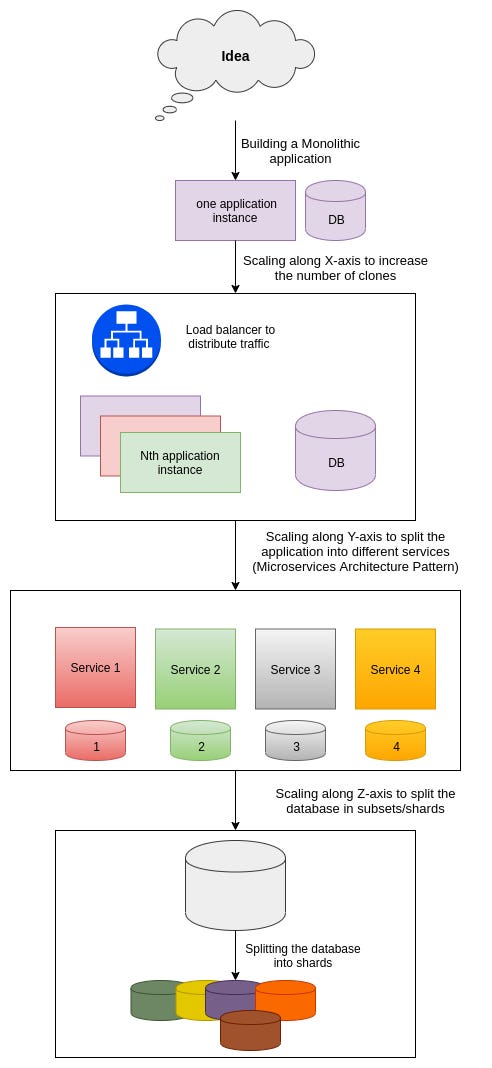
Almost all applications start small; all the functionalities are in the same codebase; there is one database and the application is deployed on one server.
When the application starts performing well and some traffic is observed on that single server, we increase the number of servers. The application is now deployed on more servers and we put a load balancer to distribute traffic among these servers. Please note: we scaled the system by adding more instances.
Now the application is performing exceptionally well but the single codebase has become too complex to add/modify any functionality. You decide to split your application into different services and follow a microservices pattern by adding different databases to different services. You can now scale different components of the application as required! Please note: we scaled the system by splitting it into different services.
Your application is not bounded by any limits and is doing phenomenally well! But some of the databases have reached their maximum potential and they are holding billions of records. The application is getting slower because of this humongous data.
You decide to split your databases into shards and put data in different clusters by applying some hash function. This is called Horizontal Partitioning of a database into shards.
Each of the shards holds some part of the entire database and may be located on separate database servers or physical locations. This technique helps in improving search performance because the index size is reduced. The number of records in each table in each database is considerably less.
We can use database sharding to keep users of different countries in different shards and query only the relevant shard for any query. Please note: we scaled the system by splitting the data store and putting chunks of data in different shards.
This pattern of scaling the application by adding more instances; splitting the application into different services; or the horizontal partitioning of the data is described as scale cube in The Art of Scalability book.
What is a Scale Cube?
The scale cube describes a model of scaling applications along its three axes:
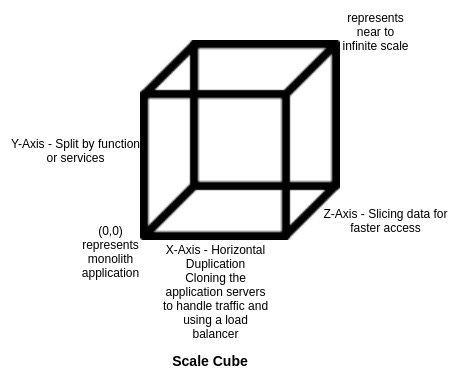
X-Axis
The X-axis represents horizontal scaling. When the load on a monolith application increases, we increase the number of application servers to handle the traffic. It simply means deploying the application on N servers so that each of the servers now handles 1/Nth of the traffic (Possibly!).
The common way of distributing traffic is to have a load balancer in place that distributes traffic in a round-robin fashion (Note: Load balancers can also be configured to distribute traffic in ways other than the round-robin).
This approach is easy to implement and scale transactions well but all the application servers use the same database. We can improve this by configuring the database replication techniques. More on Database replication techniques in the coming newsletters!
We also have to add a mechanism for handling the internal state of the application. For example, the session information of the user should be shared across all the application instances.
We can solve this by having a centralized state service to handle the state across all the application instances. The load balancer can also be used to store state-related information. We'll look at the shared session state example in detail in a moment.
Y-Axis
The Y-axis represents splitting the application by function, service, or resource. You can decide the splits based on different business capabilities such as inventory management, payments, and confirmation. The application can also be divided based on different domains. The scaling of application along the Y-axis is referred to as the microservices pattern.
This approach is difficult to implement but significantly improves the performance of the application. It facilitates small and autonomous teams to work on different parts of the application and improves the overall productivity of engineering teams.
The different teams are not dependent on each other for their respective development and deployment cycles.
Z-Axis
The Z-axis represents the split at the data level and is recommended only if the size of your database has increased beyond its capacity and it is not possible to scale it further.
This approach suggests splitting the data based on different parameters and then performing lookups only on relevant databases.
This significantly improves performance for many large enterprise applications. The data store is divided into shards that have 1/Nth of the data (Ideally!). The common way of sharding an application is by geography to store records/transactions based on different regions.
This approach of scaling the application along the z-axis provides fault isolation and improves response times.
Here's a quick overview of the transition from a monolithic application to a scalable architecture:
How do microservices solve the problems associated with monolithic applications?
Process Organization and Architecture
The microservices architecture pattern enables continuous delivery and continuous deployment and facilitates small, agile, and autonomous cross-functional teams to build applications faster.
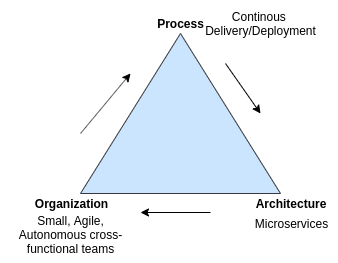
The microservices architecture enables the organization to have small teams working on a service. Jeff Bezos' two-pizza rule recommends having smaller teams for increased productivity and getting work done effectively.
Each of these teams handles a different service (read mini-application, in particular) so the inter-dependencies between different teams are vastly reduced. The teams can build and deploy their application independently and that's a big plus point!
Highly maintainable and testable services
The microservices pattern enables frequent development and release cycles and the services are easy to test. Since the codebase focuses only on one particular functionality, it is comparatively easy to track down bugs.
Flexibility with programming languages and databases
Each of the services in an application can be written in different programming languages and can also use a different database. The teams are free to choose the language of their choice and anything from RDBMS to the NoSQL database to fit their use case. This way of building applications makes it easy to upgrade the technology stack to the latest versions of the frameworks.
Loosely coupled with other services
As mentioned earlier, the services are not dependent on each other and so it is easy to build and deploy these services independently. Each of the services exposes some APIs for communicating with other services.
Packaged in different containers
The microservices are packaged in different containers and are deployed independently. The services are not dependent on any other service for their deployment cycles.
Fault Tolerance
If there is an error in one part of the application, only the service corresponding to that part is not operational. All the other services work smoothly. This is not the case with monolithic applications; a single error in one small part of the application can take down the entire application. Long live microservices!
Microservices are the developers' favorite! It is very easy to track down complex bugs and developers don't have to pull an all-nighter just to track that notorious bug. Most of the deployment-related issues are not frequent anymore. Docker and the container orchestration engines do the magic!
Better Scaling
We can scale different components of an application independently as per the need. This is not the case with the monolithic application where the entire application code needs to be cloned to achieve scalability.
We can increase the number of instances of some of the microservices without affecting the entire codebase. The traffic in these instances can be distributed using a load balancer.
Microservices look all nice and good and leave no reason to think around for their alternative. As they say, nothing in the world comes ready-made to eat and serve! You gotta prepare them!
We'll look at some of the problems associated with the microservices and then learn some cool techniques to get away with these problems.
If you think this newsletter will add any value to your knowledge base, consider subscribing using the link below:
Deep Dive into Microservices Architecture
In this section, we'll understand some of the problems associated with the microservices architecture and explore potential ways of solving them.
Let's start with the fundamental problem of additional complexity and over-head in building distributed systems and microservices:
Additional Over-head in creating a distributed system
It is comparatively easy to build a monolith -- dump all the files in the same codebase and connect a database for storing records in different tables.
In the microservices architecture, you have different services and different databases and all these components should work in sync to achieve stability and consistency.
Let's say, when a customer places an order on the website, this transaction will produce side effects on the order service as well as the payment service. We'll have to make two successful inserts into different databases for this transaction to proceed ahead.
In a way, both services seem dependent on each other for this transaction. If the payment for a transaction fails, then its corresponding entry in the orders database should be deleted. At the end of a transaction, the application should be in a consistent state.
The database in a monolithic application follows the ACID (Atomicity Consistency Isolation Durability) paradigm. The system is in a consistent state at the end of the transaction (all of the individual local transactions in different tables are either committed or aborted).
How do you maintain Isolation and Consistency with distributed transactions? How are distributed transactions done in the first place?
Hold on! There are ways to handle transaction management in distributed systems. We'll look at the solutions to these problems in the next section.
In the monolithic way of doing things, we just have to call a function for communicating with different parts of the application. This is, however, not true in the microservices architecture. Since different services are probably on different servers, we'll have to build a mechanism to communicate with these services. The HTTP calls can do the trick. If there is any query that needs inputs from two or more services, we can get the required data by making an HTTP call.
But who will facilitate this HTTP call?
When should the other service return the response to this call -- when the processing is done or just immediately? Should the service itself make the call to the other services?
We'll look at the answers to these interesting questions in the later part of the chapter.
How to divide an application into different services?
Your monolithic application has grown too complex and adding or modifying any feature has become a tedious task.
Side note: Moving to microservice involve huge operational cost and takes several iterations to get the job done. Also, it is completely fine to stick to the monolithic application if it is doing its job well. Don't just rush to achieve the next newer style out there! All the big companies started with a monolith and moved to the microservices pattern when the scale of their business capabilities increased manifolds.
If your business and the application requirements are growing fast and the old monolith is not able to sustain the burden, you can start porting your monolith to the microservices pattern. This means scaling your application along the y-axis of the scale cube by dividing the huge monolithic codebase into loosely coupled microservices.
Here are some of the strategies to help you convert the monolithic application to microservices:
Splitting the presentation and the business logic layers
Splitting the front end and the back end looks like an intuitive approach. We can start by splitting these two parts into different services. The backend service will expose APIs for the front-end and the front-end will accordingly call these APIs as per the interactions on the user interface.
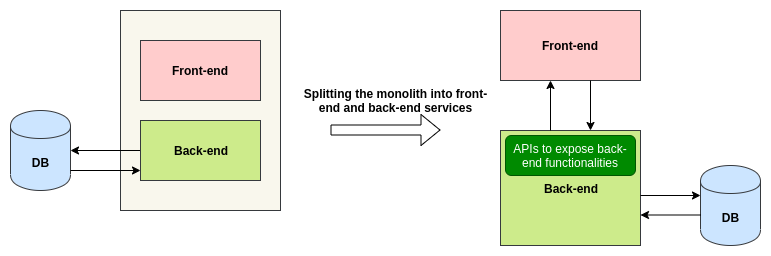
This technique will help us in scaling both these components independently as per the need. But it does not solve the original problem of splitting the monolith into different services. The front-end and the back-end services might grow to the point to become big monoliths.
Adding a new feature as a service
We can start adding new features as services. These services will expose APIs to interact with the monolithic application. Please note: this service will not be an ideal independent microservice as of yet. It can modify the database of the original application.
The transition to microservices using this technique will take time and the old modules in the monolithic application are still to be modeled as microservices. But this technique helps in keeping the monolith in stable shape.
This service is not completely isolated from the monolith and shares some glue code with the original application. The service is sometimes also called the Anti-corruption layer; it has its domain model and does not get corrupted with the old monolith code.
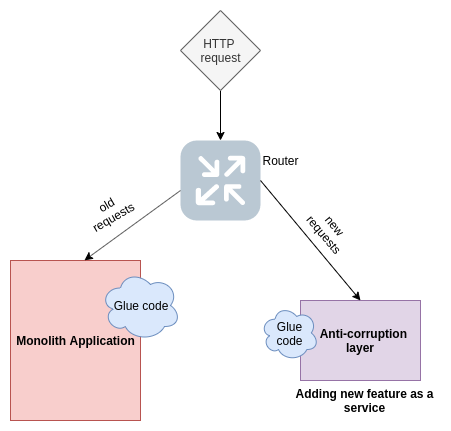
Splitting different modules and implementing them as independent services
We can extract different modules from the application and build them as services. Each of these services will expose APIs to communicate with the rest of the modules.
It is ideal to extract modules that have significant resource requirements like intensive CPU computations or high memory usage. We can package these modules into different services and allot them the resources as needed. This helps us in allocating resources smartly only to those parts that need them.
We can also extract the modules that use an in-memory database. This will be built as an independent entity and deployed in separate servers with a large amount of memory.
The modules that communicate using asynchronous messages with the rest of the application are also ideal fits to model as services.
These techniques will reduce the burden on the monolithic application and eventually different parts of the application would be isolated into different services.
Communication between microservices using HTTP and gRPC
We have now successfully isolated different services; each has its database. These services also expose APIs to communicate with other parts of the application. Let's say a customer service needs to get some data from the transactions service:
The customer service can talk to the transaction service using a dedicated interface. No service can directly modify the database of any other service. They communicate through an interface and the dedicated service will then talk to its database to get the required results.
The communication can be done using HTTP calls or by using gRPC (General Remote Procedure Call).
How to reuse code across different microservices?
We have been told to use DRY (Do not repeat yourself!) from the start of our careers. If you find a code snippet that is being used at multiple places in the codebase, you simply extract the common part and put it in a separate module, and then import this common module across different functionalities.
This is a cleaner approach and helps in writing maintainable code. If something needs to be changed in this common module, you don't have to do it at multiple places; you just have to modify the common module!
Let's consider the example of a logger. We write a service for implementing different functions for the logger module and inject/import this module into other modules. This approach of reusing code suits best in monolithic applications where the common modules and the services are in the same codebase and you just have to import them.
In the microservices architectural style, the codebase for different functionalities is isolated and resides at different locations.
The microservice follows the fundamental principle of having loosely coupled services in an application. The services should not be dependent on any other service; they should be self-contained to operate on their own.
If we were to integrate logging in multiple services, we'll have to write that part of the code in all of the services that require logging functionality. This violates the DRY principle but fits in the fundamental aspect of microservices.
Using DRY in microservices is a debatable topic!
Some people suggest adhering to the microservices pattern and copy-pasting the common functionalities in different services while others suggest bending this rule a bit!
We can have a common shared library to put all the common functionalities and this library can be used by different microservices. We can implement a service for a logger that other microservices can simply import and start using it. This common module is now tightly coupled to these microservices. The team handling this module should communicate the changes to the dependent microservices team. This again violates the idea of having loosely coupled microservices!
Some companies are using the code reuse pattern effectively. We should share code snippets to an extent and don't overdo it! We should be sharing modules that are unlikely to change at least for some months.
For example, the SMS/Email sending libraries, and loggers, are not changed too often and are like build once and use forever type of modules. These modules can be extracted in a shared repository.
How to set up Authentication and Authorization in the microservices architecture?
Authentication is the act of identifying "who you are?" while Authorization checks "what you can do?"
The process of authentication checks if the credentials of the user are valid and his record exists in the system. The users generally log into the application using a combination of username and password.
When a user logs into the application, a sessionId is generated against his credentials and this sessionId can be saved in a shared state of the application instances or a particular sessions table in the database.
The sessionId is returned as a response to the login request. It is stored in the session storage or the local storage of the client (browser) and is passed along with the subsequent requests.
The client usually makes API requests to the server using the HTTP protocol and HTTP is stateless. The HTTP does not remember the past states and so this sessionId is to be sent explicitly with each request. We don't have to validate the user credentials on every request; we simply check if this particular sessionId is present in the sessions table.
Here's the typical workflow:
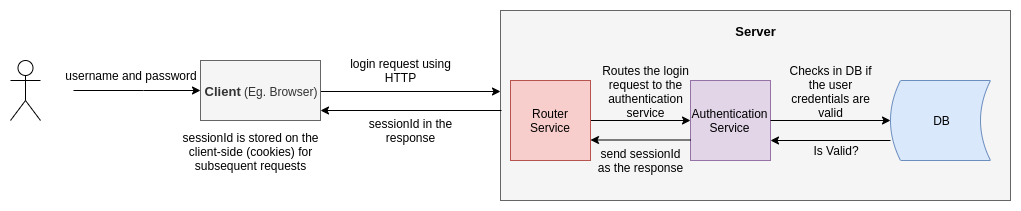
In the above image, the application is deployed on one server. The sessionId is stored in the state/cache of that server. If we increase the number of servers, this sessionId information should be shared across these servers. If this is difficult to grasp, don't worry! We'll get into the details of this bit.
Let's say you have 3 application servers. The load balancer routes the login request to the 1st server and it stores the session information in its local cache. The other two servers are unaware of these details.
The load balancer might route the second request of the same user to the 2nd server. Since the 2nd server does not know the validity of the user (session information), the user might have to put in his credentials again. This might happen for all the subsequent requests and is a bad user experience. We'll have to think of a better solution!
Can we store the session-related information in a shared database so that it becomes easy for all the servers to validate user sessions?
This approach makes this shared database a critical dependency and any failure in this part will take down the entire application.
Can we store the session information on all of the servers?
Again, this doesn't look like an efficient solution. We'll be wasting too much memory to store duplicate records.
Can we have sticky sessions?
The load balancer should route the login and other subsequent requests to the same server. If server 1 has validated the user and has his session information stored in the local cache, all the requests from this user should be routed to this particular server. This approach solves the problems but creates an additional complexity of routing the requests to particular servers.
Can we store all of the session information in the load balancer?
The load balancer will validate the session and then would pass on the request to the application server. This looks like a viable solution. But we can do better!
How does Netflix handle the authentication problem in its microservices architecture?
Can we have a dedicated authentication service to take care of this and then route to particular servers handling the business logic?
Why not? Yes, it's better to have a dedicated service for dealing with authentication.
The idea of putting authentication logic in each of the services involves a lot of repetition work and adds to the complexity of the application. Let's learn more and find out how Netflix is solving this problem!
Netflix does the authentication, authorization, security, and other exciting work in one of the components called Zuul.
Zuul is the front door for all requests from devices and web sites to the backend of the Netflix streaming application. As an edge service application, Zuul is built to enable dynamic routing, monitoring, resiliency and security. - Zuul Wiki
This looks like an excellent solution for handling authentication and authorization in the microservices architecture. The internal working of Zuul is not in the scope of this book but you can go ahead and read its documentation to know more.
There are a few more interesting issues in the microservices journey which we’ll look at in the next edition of the newsletter. Stay tuned!
If you enjoyed this post and learned something from it, please share it and help reach this post to more readers. Thank you!